The JSON format is really interesting to store highly structured information.
In this module, we will see how it maps naturally on the Dict data
structure, how to use it to load and save data, and how to print the contents
of a JSON file. As an illustration, we will look at the time series of
vaccination against COVID-19 in New Zealand.
In Julia, the JSON package handles all of the JSON related tasks.
import Downloads
import JSON
To illustrate how JSON works (and brush up on our Downloads skills!), we will download the COVID-19 vaccination data from the Our World In Data project. They are openly available on GitHub:
vax_url = "https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/vaccinations/vaccinations.json"
"https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/vaccinations/vaccinations.json"
We can now add this callback to our download function:
vax_data = Downloads.download(vax_url)
"/tmp/jl_wX4fe1YXsv"
In order to read this file, we can use the parsefile function. Note that the
file is really large (it has one entry for every tracked locality, a mix of
countries and continents).
vax = JSON.parsefile(vax_data);
We can get a look at the type of data:
eltype(vax)
Any
JSON stores a combination of arrays and dictionary, which are usually nested within one another. In order to make our problem more tractable, let’s focus on the vaccination data for New Zealand:
nz_vax = only(filter(x -> x["iso_code"] == "NZL", vax))
collect(keys(nz_vax))
3-element Vector{String}:
"iso_code"
"data"
"country"
The "data" entry in the dictionary stores daily information on vaccination
– let’s zoom in on the first day:
nz_vax["data"][1]
Dict{String, Any} with 5 entries:
"total_vaccinations_per_hundred" => 0.0
"total_vaccinations" => 1
"people_vaccinated" => 1
"people_vaccinated_per_hundred" => 0.0
"date" => "2021-02-14"
Based on this, we might want to extract the date and number of vaccinated
people per hundred. One particularity of JSON is that it does not store
information about the types, as evidences by the fact that our dictionary is a
Dict{String, Any}. So maybe a more tractable format is to get a dictionary
with an initial timepoint (day of the first vaccination), then an array of
days elapsed since (using Dates), and an array of numbers representing the
percentage of vaccinated people. This could, for example, be used to compare
the time it took for different countries to reach different portions of
vaccination coverage.
We will create empty arrays (after a preliminary inspection of the dataset, not all days have the correct key we are looking for):
import Dates
dates = Dates.Date[]
coverage = Float64[]
Float64[]
And we can now iterate over the JSON structure, apply the correct type as we go, and grow the array as we have done in a previous module:
for day in nz_vax["data"]
if haskey(day, "people_vaccinated_per_hundred")
push!(dates, Dates.Date(day["date"]))
push!(coverage, day["people_vaccinated_per_hundred"])
end
end
Let’s get the initial time:
day_0 = dates[1]
2021-02-14
And the number of days elapsed since:
days_elapsed = [Dates.value(day - day_0) for day in dates]
days_elapsed[1:5]
5-element Vector{Int64}:
0
1
3
5
6
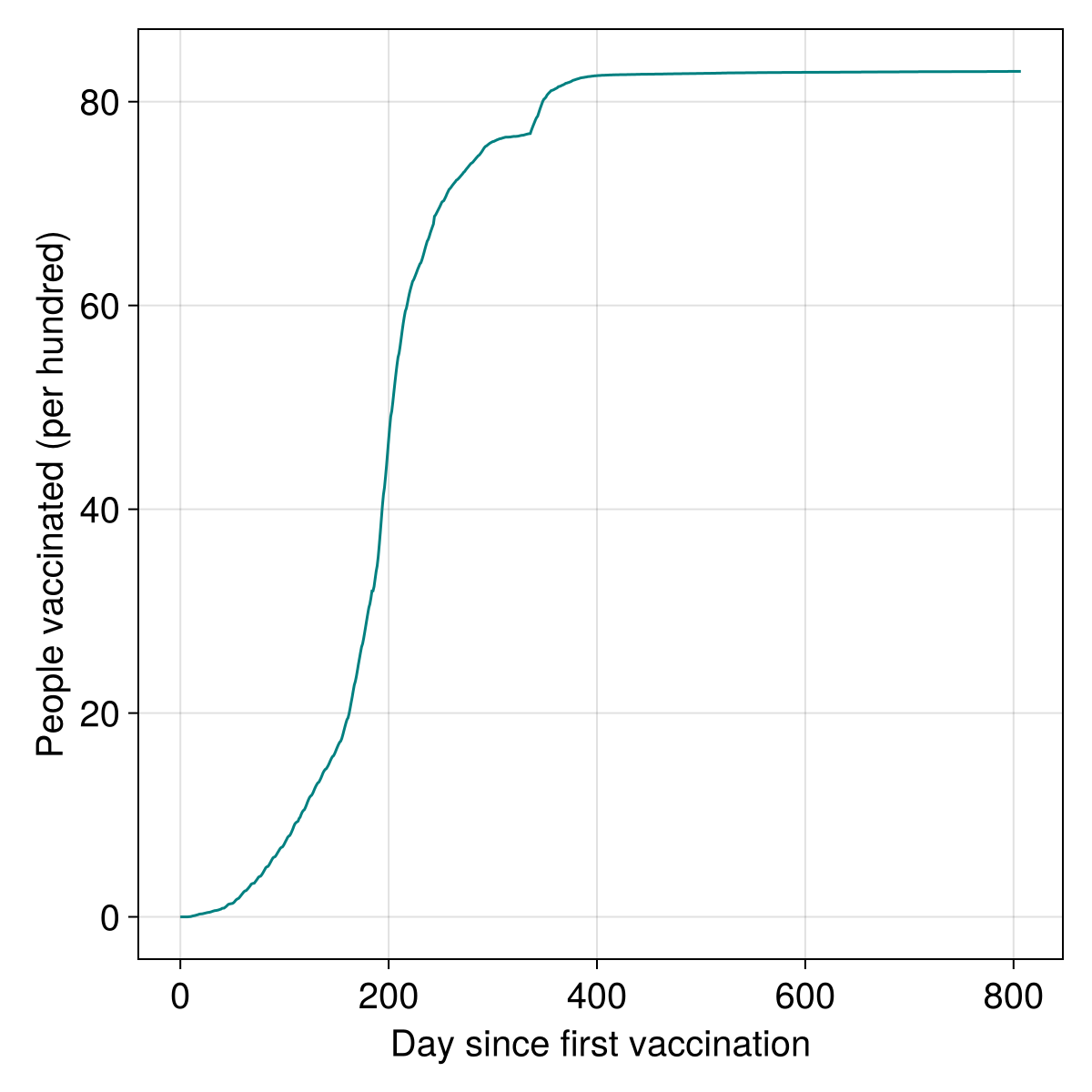
We can finally plot these data:
using CairoMakie
CairoMakie.activate!(; px_per_unit = 2) # This ensures high-res figures
figure = Figure(; resolution = (600, 600), fontsize = 20, backgroundcolor = :transparent)
scplot = Axis(
figure[1, 1];
xlabel = "Day since first vaccination",
ylabel = "People vaccinated (per hundred)",
)
lines!(scplot, days_elapsed, coverage; color = :teal)
figure
But now – how do we keep this data for future analysis? We can store them in a JSON file! In order to make this possible, we can create a dictionary:
subset_nz_vax = Dict(
"day0" => day_0,
"timeseries" => days_elapsed,
"percent_vaccinated" => coverage,
)
collect(keys(subset_nz_vax))
3-element Vector{String}:
"day0"
"percent_vaccinated"
"timeseries"
Saving a Julia object to a JSON file requires to create a file (we are using a temporary file here, but in practice we would put the file for data processing in a location within our project), and then write into this file. This is a fairly standard way of doing the open/write/close loop, that is used by most packages writing files to disk.
json_output = tempname()
open(json_output, "w") do json_file
return JSON.print(json_file, subset_nz_vax, 4)
end
In order to check that our dataset has been correctly written, we can have a look at the first ten rows of the JSON file:
readlines(json_output)[1:5]
5-element Vector{String}:
"{"
" \"day0\": \"2021-02-14\","
" \"percent_vaccinated\": ["
" 0.0,"
" 0.0,"
In summary, the JSON package allows to read data in the structured JSON format, and to write them in the same format. A very common usage loop is to:
- Get data from an online location
- Parse these data as Julia objects ready to be used in an actual analysis
- Save the formatted data for re-use, while keeping the structure
In short, JSON is very interesting as something in between tabular formats and full databases. In the next section, we will see that many web services “speak” JSON as their native language, allowing to use it to interact with remote data.